Disjoint Set(분리집합)이라고도 한다.
서로 중복되지 않는(교집합이 없는) 둘 이상의 집합의 정보를 저장, 조작하는 자료구조이다.
유니온 파인드는 3가지 연산이 존재한다.
make - set(x)
: 초기화를 하는 연산이다. x를 원소로 하는 새로운 집합을 생성한다.
이때 생성되는 집합은 x만을 원소로 갖는다.
union(x, y)
: x가 포함된 집합과 y가 포함된 집합을 하나의 집합으로 합친다.
find(x)
: x가 어느 집합에 속해 있는지를 찾는다.
유니온 파인드를 구현하는 방법은 다양한데, 그 중에서도 가장 잘 알려진 트리를 이용한 방법을 설명할 것이다.
트리를 이용한 Union-Find
트리를 이용하여 유니온 파인드를 구현할 경우,
하나의 트리는 집합 1개를 의미하며 트리의 루트 노드는 해당 집합을 대표한다.
트리 = 집합
루트 노드 = 집합을 대표
무슨 말인지 이해를 돕기 위해 다음 예를 보자.
원소 1, 2, 3, 4, 5, 6이 존재한다. 그리고 처음에 초기화를 통해 6개의 원소는 각각의 집합을 이루게 된다.
즉, 원소가 자기 자신밖에 없는 집합을 이룬다. 따라서 처음에는 총 6개의 집합이 생성된다.
: makeSet()
parent[x] = x

표는 각 원소(x)와 그 원소(x)의 부모 노드(parent[x])가 무엇인지를 나타낸다.
처음에는 각각의 집합에 자기자신 밖에 없으므로 집합을 대표하는 원소가 자기 자신이 된다.
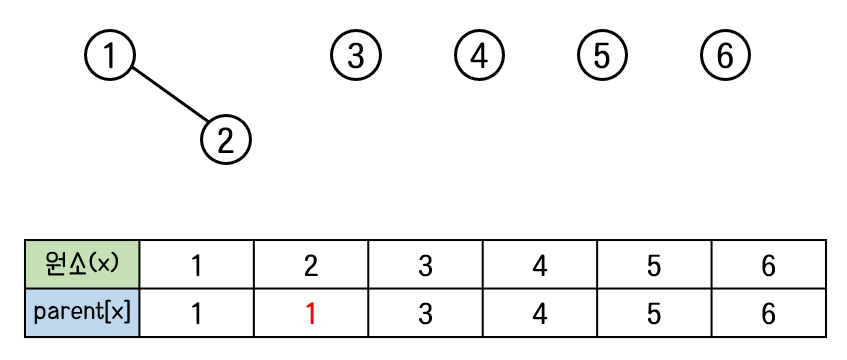
이제 원소1이 속한 집합과 원소2가 속한 집합을 합치고 싶다.
이때 필요한 연산이 union연산이며, 매개변수로 1과 2를 넣어준다.
: union(1, 2)
원소2가 속한 집합과 원소1이 속한 집합이 하나의 집합으로 합쳐지기 위해 1번 노드와 2번 노드가 연결되어야 한다. 같은 트리에 속한다는 것은 하나의 집합임을 의미하기 때문이다.
두 집합을 합칠 때는 특정 트리(집합)의 루트 노드가 다른 트리(집합)의 밑으로 들어간다. 그러기 위해서는 두 집합의 루트 노드가 무엇인지를 찾아야 하는 과정이 선행되어야 하는데, 이때 필요한 연산이 find연산이다. find(x)연산은 원소x가 속한 트리(집합)의 루트 노드 번호를 찾아준다.
따라서, 원소1의 루트 노드를 찾는 find(1)와, 원소2의 루트 노드를 찾는 find(2)연산을 먼저 수행한다.
find(1) = 1
find(2) = 2
처음에는 집합에 자기 자신뿐이므로 집합을 대표하는 번호는 자기 자신이다.
어떠한 집합을 표현할 때는 그 집합에 해당하는 트리의 루트 노드의 번호로 나타낸다.
여기서 두 집합을 합칠 경우, 두번째 매개변수로 들어간 원소2가 첫번째 매개변수로 들어간 원소1의 집합으로 합쳐진다고 가정한다.
2번 노드가 1번 노드의 자식노드로 들어감으로써 원소2가 속한 집합의 루트 노드는 1번 노드가 되었다.
따라서 원소2가 속한 집합을 대표하는 것은 1번 노드가 된다.
아래 표를 보면 원소2의 parent[2]가 2에서 1로 변경되었다.
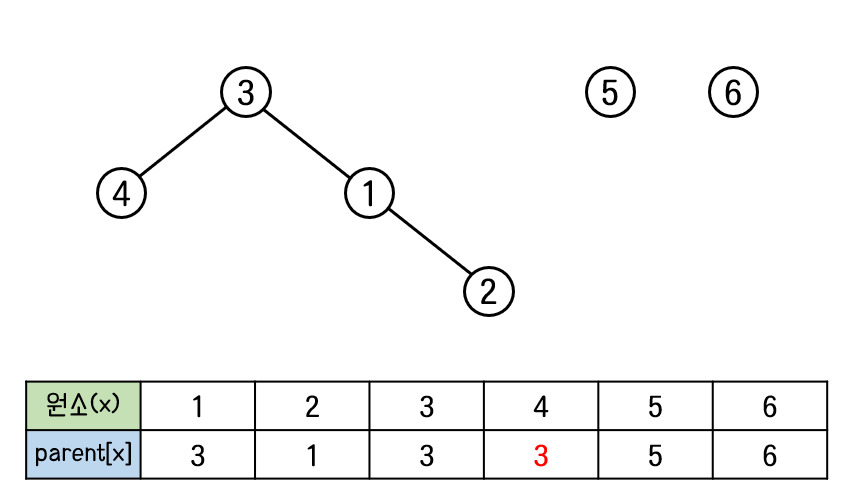
그 다음 union(3, 2)을 하면 어떻게 될까?
: union(3, 2)
원소3이 속한 집합과 원소2이 속한 집합이 하나의 집합으로 합쳐져야 한다.
두 집합이 합쳐질 때는 하나의 집합의 루트 노드가 다른 집합의 밑으로 들어간다.
원소2가 속한 집합의 루트 노드는 1번이다. (find(2) = 1)
따라서 1번 노드가 3번 노드의 자식노드로 들어간다.
이렇게 함으로써 원소1, 2, 3이 하나의 트리를 이루어 하나의 집합으로 합쳐진다.

: union(3,4)
원소3이 속한 집합과 원소4가 속한 집합을 합친다.
원소4가 속한 집합의 루트 노드는 자기 자신인 4번 노드이다. 4번 노드가 원소3이 속한 집합의 루트 노드인 3번 노드의 자식노드로 들어간다.
이제 나머지 과정들도 그림을 통해서 변화를 확인하자.
: union(5,2)
find(2) = 3, find(5) = 5이므로 3번 노드가 5번 노드의 자식노드로 들어간다.

: union(5,6)

아래는 트리를 이용한 Union-Find 구현 시, makeSet, find, union 알고리즘의 코드이다.
makeSet(x)
public void makeSet() {
for (int i = 1; i < parent.length; i++) {
parent[i] = i; // 각 원소의 루트 노드는 자기 자신이다.
}
}find(x)
public int find(int x) {
if (parent[x] == x)
return x;
return find(parent[x]);
}union(x, y)
public void union(int x, int y) {
x = find(x); // 원소x의 루트 노드 찾기
y = find(y); // 원소y의 루트 노드 찾기
parent[y] = x;
}
Union-Find 최적화
유니온 파인드의 예제와 3가지 연산 makeSet, find, union의 코드를 살펴보았다.
그런데 위의 코드를 사용하여 유니온 파인드를 구현하면 비효율적인 경우가 있다.
find 연산 최적화 : Path Compression
먼저, find연산의 경우를 보자. find연산은 현재 노드의 부모 노드를 계속 거슬러 올라가면서 최종 루트 노드를 찾는다.
그런데 만약 다음과 같은 트리에서 find연산을 수행한다고 하면 어떨까?

find(n)을 수행하면 n번 노드부터 시작하여 부모 노드를 거슬러 올라가는 행위를 총 n-1번 반복한다.
이렇게 트리가 비대칭 구조를 이루는 경우에는 최악의 경우가 되어 시작복잡도가 O(n)이 된다.
그래서 등장한것이 경로 압축(Path Compression)이다.경로 압축이란 트리의 루트 노드를 제외한 모든 노드들이 루트 노드의 자식노드가 되도록 트리를 압축하는 방법을 말한다.

경로 압축은 다음과 같이 코드를 수정하여 구현할 수 있다.
public int find(int x) {
if (parent[x] == x)
return x;
return parent[x] = find(parent[x]);
}기존의 코드와 달라진 점은 두번째 return문이다.
return parent[x] = find(parent[x])
재귀를 통해 원소x의 부모 노드(parent[x])의 루트 노드를 찾으면, 원소x의 부모 노드를 루트 노드로 변경한다. 아래 그림을 보자.
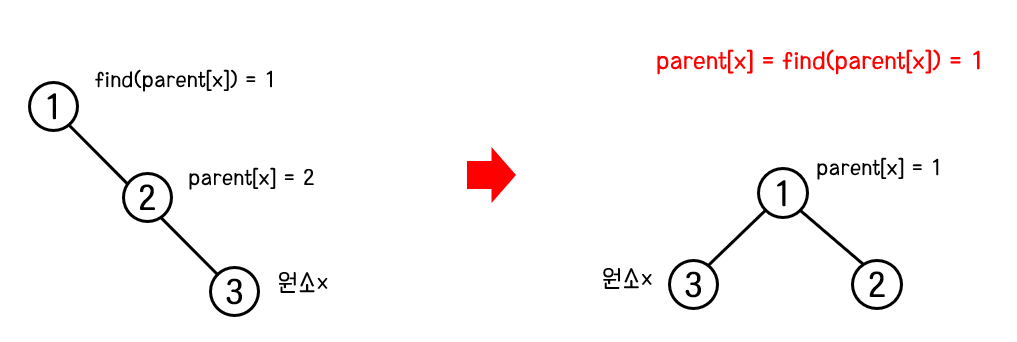
원소3의 부모 노드는 2번 노드였다. 그리고 2번 노드가 속한 트리의 루트 노드(find(parent[2]))는 1번 노드이다. 여기서 원소3의 부모노드를 find(parent[2])로 바꾸면 원소3의 부모 노드는 1번 노드 즉, 루트 노드가 된다. 경로 압축이 일어난 것이다.
이런식으로 find연산 과정에서 경로 압축을 해가면 트리가 비대칭 모양이 되는 것을 피할 수 있으며 따라서 시간 복잡도는 O(n)에서 O(logn)으로 변경된다.
union 연산 최적화 : Union - By - Rank
기존의 union(x, y)연산에서는 두번째 인자로 들어간 원소(y)의 집합이 첫번째 인자로 들어간 원소(x)의 집합에 융합되었다. 하지만 무작정 두번째 원소의 집합이 첫번째 원소의 집합 밑으로 들어가는 것보다, 집합(트리)의 높이에 따라 어느 집합이 다른 집합으로 융합될 지를 결정하면 더 효율성을 높일 수 있다.
다음과 같이 집합A를 나타내는 트리와, 집합B를 나타내는 트리가 있다고 하자.
집합A의 루트 노드는 1번 노드이며 트리의 높이는 3이다.집합B의 루트 노드는 7번 노드이며 트리의 높이는 2이다.

먼저, 집합A의 루트 노드를 집합B의 루트 노드의 자식 노드로 연결하면 다음과 같다.
집합A의 루트 노드인 1번 노드가 집합B의 루트 노드인 7번 노드의 자식 노드로 들어감으로써
두 집합이 하나로 합쳐지면서 전제 트리의 높이는 4가 되었다.

그렇다면 이번에는 집합B의 루트 노드를 집합A의 루트 노드인 1번 노드의 자식 노드로 합쳐보자.
7번 노드가 1번 노드의 자식 노드로 들어감에 따라 전체 트리의 높이는 3이 되었다.

위의 결과를 보면, 트리의 높이가 높은 집합을 트리의 높이가 낮은 집합에 합쳐질 때보다, 트리의 높이가 낮은 집합을 트리의 높이가 높은 집합에 합칠 때 전체 합쳐진 트리의 높이가 더 작다는 사실을 알아낼 수 있다.
Union-By-Rank는 union연산을 수행할 두 트리의 높이를 비교하여, 높이가 작은 트리를 높이가 높은 트리의 자식 트리로 들어가도록 하여 전체 트리의 높이를 줄이도록 하는 방법이다.
위의 예시에서는 두 트리의 높이 차이가 1뿐이지만, 계속해서 union연산을 실행한다고 생각하면 트리의 높이 차가 계속 누적되어 나중에는 큰 차이를 보일 것이다.
Union-By-Rank에서는 각각의 집합을 의미하는 트리의 높이 정보를 저장할 변수가 별도로 필요하다.
따라서 rank라는 배열을 생성하여 원소x가 속한 트리의 높이를 rank[x]에 보관한다.
public void union(int x, int y) {
x = find(x);
y = find(y);
if (x == y)
return;
if (rank[x] < rank[y]) // 원소y가 속한 트리의 높이가 더 높은 경우
parent[x] = y;
else if (rank[x] > rank[y]) // 원소x가 속한 트리의 높이가 더 높은 경우
parent[y] = x;
else if (rank[x] == rank[y]) { // 두 트리의 높이가 동일한 경우
parent[y] = x; // parent[x]=y; // 아무 경우나 상관없음
rank[x]++; // rank[y]++; // 전체 트리의 높이는 1 증가한다.
}
}
아래는 rank배열을 초기화 하는 과정이다. 기존의 makeSet() 메서드에 rank배열을 초기화 하는 코드를 추가한다.
public void makeSet() {
for (int i = 1; i < parent.length; i++) {
parent[i] = i;
rank[i] = 0;
}
}
Union-Find 전체 코드
static class DisjointSet {
int[] parent;
int[] rank;
DisjointSet(int n) {
parent = new int[n];
rank = new int[n];
}
public int find(int x) {
if (parent[x] == x)
return x;
return parent[x] = find(parent[x]);
}
public void union(int x, int y) {
x = find(x);
y = find(y);
if (x == y)
return;
if (rank[x] < rank[y])
parent[x] = y;
else if (rank[x] > rank[y])
parent[y] = x;
else if (rank[x] == rank[y]) {
parent[y] = x; // parent[x]=y;
rank[x]++; // rank[y]++;
}
}
public void makeSet() {
for (int i = 1; i < parent.length; i++) {
parent[i] = i;
rank[i] = 0;
}
}
}
}