어떤 문자열(T)에서 특정 문자열(P)를 찾을 때 사용하는 알고리즘
예를 들어,
문자열(T) : "CDABABKABADABABC"
문자열(P) : "ABABC"
문자열 T에서 문자열 P를 찾는 방법을 단순하게 완전탐색으로 구현해보면 이중 for문을 통해 다음과 같이 구현해 볼 수 있다.
String T="CDABABKABADABABC"
String P="ABABC"
for(int i=0;i<T.length()-P.length();i++){
String tmp="";
for(int j=0;j<P.length();j++){
tmp+=T.charAt(i+j); // i번째부터 i+P.length()까지의 문자열 추출
}
if(tmp.equals(P)){ // 추출한 문자열 tmp가 문자열 P와 동일하면 탐색 성공
System.out.println("탐색 성공!");
break;
}
}
문자열 T를 반복문을 통해 차례대로 탐색하면서 문자열 P를 찾는 방식으로, 가장 쉬운 구현 방법이다. 말 그대로 문자열 T의 문자 하나하나 전부 비교하여서 문자열 P가 존재하는지 찾는 것이다. 바깥쪽 for문은 T의 길이만큼 반복하고, 안쪽 for문은 P의 길이만큼 반복하므로, 시간복잡도는 O(n*m) (n는 T의 길이, m은 P의 길이)가 된다.
그렇다면, 다음의 경우는 어떨까?
문자열 T(Text)에서 문자열 P(Pattern)를 찾는 과정을 아래 그림을 통해 순차적으로 살펴보자.
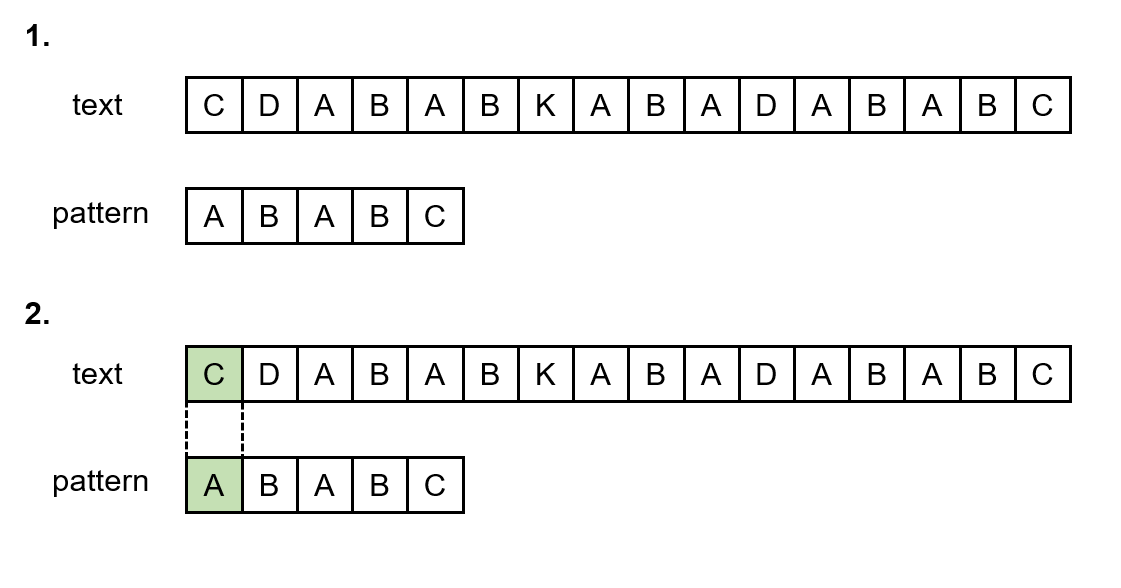




1~3. text의 첫번째 문자와 두번째 문자인 'C', 'D'는 pattern의 첫번째 문자와 두번째 문자인 'A', 'B'와
일치하지 않는다. 따라서 일치하는 문자가 나올 때까지 pattern이 오른쪽으로 한칸씩 이동한다.
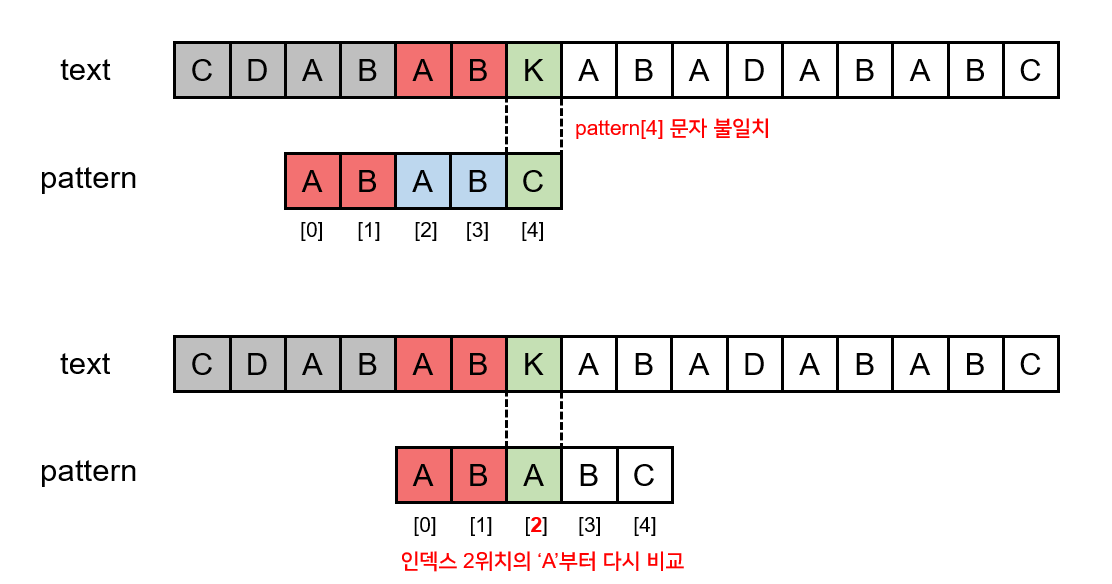
4. 세번째 문자는 Text에서도 'A'이고, Pattern에서도 'A'이므로 문자가 일치한다.
5~7. 그 뒤로도 계속 문자가 일치한다. -> 'B' 'A' 'B'
8. 그 다음 문자가 text의 경우 'K'이고, pattern의 경우 'C'이므로 일치하지 않는다.
9. 그림을 보면, 이번에는 pattern이 오른쪽으로 총 두 칸을 건너뛰었다.
pattern의 첫 번째, 두 번째 문자인 'A', 'B'가 text에서 'K' 다음의 문자인 'A', 'B'와 일치하므로 굳이 다시
비교를 할 필요가 없기 때문이다.
여기서 KMP 알고리즘의 특징이 나타난다.
즉, 위에 보았던 코드에서는 무조건 한칸씩 비교를 했기 때문에 총 O(n*m)라는 시간복잡도가 걸렸다. 하지만 KMP 알고리즘에서는 상황에 따라 비교할 대상을 건너뛰면서 탐색을 진행하기 때문에 위의 코드보다 더 효율적으로 패턴을 찾을 수 있다는 장점이 있다.
KMP 알고리즘은 크게 두 가지 과정으로 나눌 수 있다.
1. 건너뛰기 표 만들기
특정 문자가 일치하지 않을 경우, 몇 번째 문자부터 다시 비교를 하면 되는지 그 위치를 배열 skip에 저장
2. text 문자열에서 pattern 찾기
skip 배열을 바탕으로, 패턴을 오른쪽으로 적절히 이동시키면서 탐색
건너뛰기 표 skip[idx] 의 의미 :
패턴의 idx번째 문자를 비교했을 때, 일치하지 않는다면 그 다음에 비교를 해야할 문자의 위치
위의 예시대로 라면, 패턴 "ABABC"에서 'C'의 비교 후, 다시 패턴의 처음부터 비교를 하는 것이 아니라 2번째 문자부터 비교를 했으므로 skip[4] = 2 이다.
1. 건너뛰기 표 만들기
KMP 알고리즘은 skip 배열을 만들고, 이 배열에 얼마나 이동해야하는지 그 칸 수를 저장한다는 것을 알았다.
그렇다면 이 skip 배열은 어떻게 채워넣을 수 있을까?
KMP 알고리즘을 사용하는 목적을 다시한번 생각해보자. KMP 알고리즘은 text에서 패턴과 일치하는 문자열이 존재하는지를 확인하는 알고리즘이다. 그런데 지금 패턴의 4번째 문자를 비교 중이라는 것은 0번째~3번째 문자는 이미 일치한다는 뜻이다.
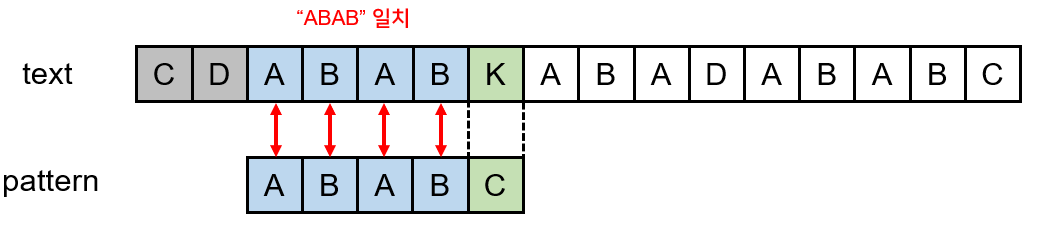
이 때, 이미 비교를 완료한 0번째~3번째 문자 사이에서 중복되는 문자열이 있다면?
패턴의 "ABAB"에서 앞의 "AB"와 뒤의 "AB"는 문자열이 동일하다. 그리고 앞의 "AB"와 뒤의 "AB"는 이미 text에도 존재한다. 그렇다는 얘기는 패턴이 오른쪽으로 한칸씩 이동하다가 앞의 "AB"는 text와 일치하는 경우가 분명히 나타난다는 뜻이다.
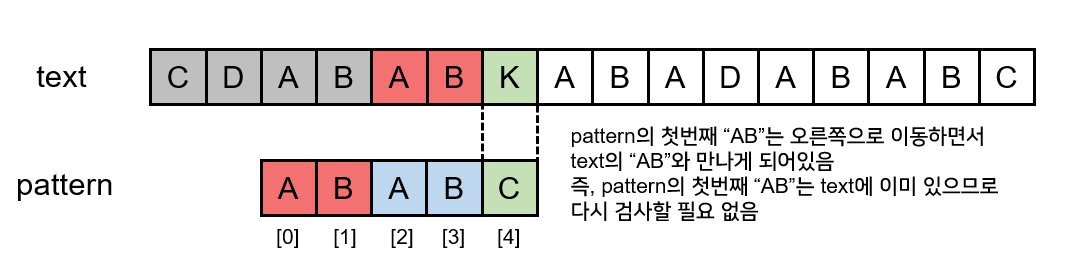
따라서, skip배열을 채워넣기 위해서는 패턴 내에서 동일한 부분문자열이 존재하는지를 확인하는 것이 관건이다. 이를 위해서는 패턴과 패턴의 비교를 진행한다. 이를 위해 text도 "ABABC", pattern도 "ABABC"로 설정하여서 이 둘 사이에 일치하는 문자열이 존재하는지를 확인하면 된다.
> pattern과 pattern의 비교
text와 pattern을 비교한 것과 마찬가지로 pattern과 pattern의 비교도 비슷한 방식으로 이루어진다. 따라서 pattern과 pattern을 비교하는 알고리즘을 이해하고 나면, text와 pattern을 비교하는 알고리즘도 이해하기가 쉬울 것이다.
우선 건너뛰기 표로 사용하게 될 skip배열을 생성한다.
int[] skip = new int[pattern.length()+1];
여기서는 두 개의 pattern을 비교하기 위해서 하나는 text, 하나는 pattern으로 취급한다.
둘 사이의 비교를 위해 text에서 현재 위치를 가리키는 변수를 pt(pointer Of text), pattern에서 현재 위치를 가리키는 변수를 pp(pointer Of Pattern)이라고 정한다. 처음에는 text에서는 0번째 문자부터, pattern에서는 1번째 문자부터 비교를 하기 때문에 pt = 0, pp = 1로 초기화를 한다.

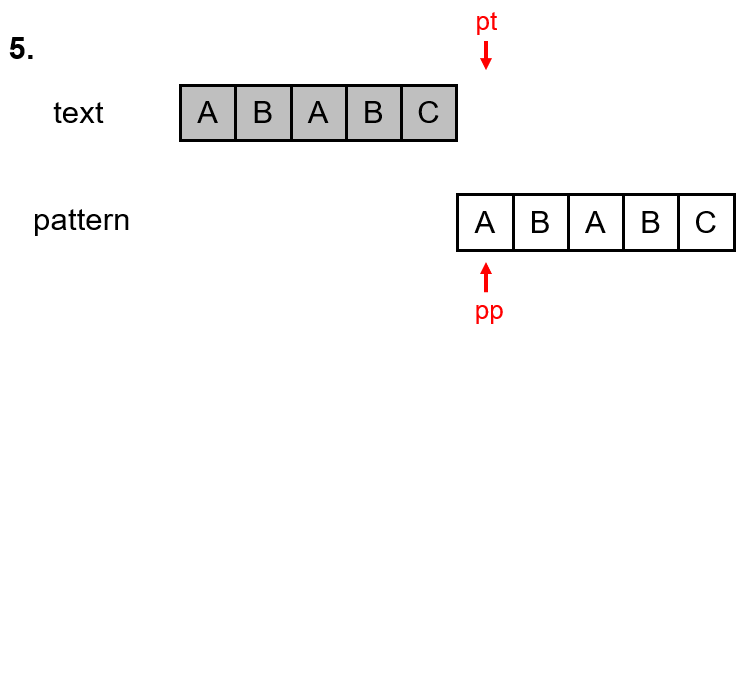
1. 'B'와 'A'는 일치하지 않는다. 패턴의 0번째부터 다시 비교를 해야하므로 pp는 그대로 0이며, pt는 한칸 이동한다.
2. 'A'와 'A'는 일치한다. 이 얘기는 pattern 문자열 내에 'A'가 적어도 2번 있다는 뜻이 된다.(0번째, 2번째)
따라서, 앞으로의 진행에서 문자가 불일치하는 일이 발생할 경우, 다시 패턴의 처음으로 돌아가서 비교를 할 필요 없이 'A'의 다음인 1번째 문자부터 비교를 하면 된다. 적어도 패턴의 0번째 문자는 다시 비교할 필요 없이 건너뛸 수 있는 것이 보장된 셈이다.
-> skip[3] = 1
즉, 만약 1번째 문자가 일치하지 않아도, 패턴의 처음으로 돌아가지 않고, 1번째부터 다시 비교하면 된다.
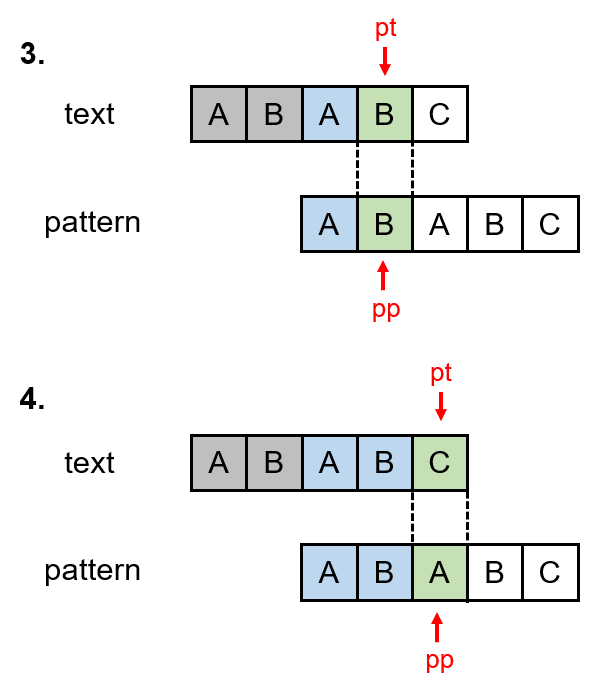
3. 'B'와 'B'는 일치한다. 마찬가지로 pattern 문자열 내에 'B'가 적어도 2번 있다는 뜻이 된다.(1번째, 3번째) 따라서, 앞으로의 진행에서 문자가 불일치하는 일이 발생할 경우, 다시 패턴의 처음으로 돌아가서 비교를 할 필요 없이 'AB'의 다음인 2번째 문자부터 비교를 하면 된다.적어도 패턴의 0, 1번째 문자는 다시 비교할 필요 없이 건너뛸 수 있는 것이 보장된 셈이다.
-> skip[4] = 2
즉, 만약 2번째 문자가 일치하지 않아도, 패턴의 처음으로 돌아가지 않고, 2번째부터 다시 비교하면 된다.
4. 'C'와 'A'는 일치하지 않는다. 그렇다면, 다시 패턴의 처음으로 돌아가야 할까? 아니다. 현재 pp = 2이고, 패턴의 2번째 문자가 일치하지 않는 경우에는 skip[2]에 저장된 위치로 이동하면 된다고 했다. 방금 3번에서 "AB"가 패턴에 적어도 두 번 존재하므로 건너뛰고, 2번째부터 비교를 하면 된다는 결론이 나왔다. 그에 따라 skip[2]에는 2를 저장하였다.
따라서, pp = skip[2]를 대입하여서 패턴의 2번째 문자부터 다시 비교를 시작한다.
5. pp = 2가 되지만, pt가 배열의 범위를 벗어났으므로 탐색을 종료한다.
위의 과정을 진행하면서 저장된 건너뛰기 표 skip은 아래와 같다.

정리하자면 pattern[pt] 와 pattern[pp] 와의 비교에서, 크게 세가지 경우로 케이스가 나뉜다.
case 1.
pattern[pt] != pattern[pp] 일 때, pp = 0 인 경우, 즉 패턴의 처음부터 일치하지 않는 경우에는 0번째 문자부터 다시 비교해야하므로 skip배열에는 0이 들어간다.
skip[pt+1] = 0; pt++; pp=0;
case 2.
pattern[pt] != pattern[pp] 일 때, pp > 0 인 경우, 즉 그 전까지는 일치하다가 패턴의 중간부터 일치하지 않는 경우에는 skip[pp]에 저장된 위치로 이동하여 해당 위치부터 문자를 비교한다.
pp = skip[pp];
*skip[idx] : idx번째 문자가 일치하지 않을 때, 다시 비교해야할(되돌아가야할) 위치
(무조건 처음으로 되돌아가서 비교하지 않는다는 것이 KMP 알고리즘의 특징이다. 그리고 이 KMP 알고리즘을 실현하기 위해 필요한 것이 skip 배열이었다.)
case 3.
pattern[pt] == patter[pp] 일 때, pattern의 pp번째 문자가 일치한다는 것은, 패턴의 0~pp번째 문자열과 일치하는 문자열이 패턴에 두번이상 존재한다는 의미이다. 그렇다면 만약에 pattern[pt+1]와 pattern[pp+1] (패턴의 그 다음 문자)를 비교해서 일치하지 않는 상황이 발생할 경우, 다시 비교를 시작해야하는 지점은 pp+1이다.
skip[pt+1] = pp +1; pt++; pp++;
코드로 나타내면 아래와 같다.
int pt=1;
int pp=0;
int[] skip=new int[pattern.length()+1];
while(pattern<text.length()){
// 두 문자가 일치하는 경우
if(pattern.charAt(pt) == pattern.charAt(pp)){
skip[++pt] = ++pp;
}
// 두 문자가 일치하지 않고, 패턴의 처음부터 일치하지 않는 경우
else if(pp == 0){
skip[++pt] = 0;
}
// 두 문자가 일치하지 않고, 패턴의 중간부터 일치하지 않는 경우
else{
pp=skip[pp];
}
}
2. text 문자열에서 pattern 찾기
이제 만들어진 건너뛰기 표를 이용하여 text의 탐색을 진행해본다.
방금 건너뛰기 표를 만들 때의 알고리즘과 비슷하다.
pattern에서 pattern과 일치하는 문자열을 찾는 것과, text에서 pattern과 일치하는 문자열을 찾는 것.
이 두 가지 모두 동일한 흐름이기 때문이다.
마찬가지로 알고리즘을 진행하면서 세가지 케이스로 나뉘어진다.
case 1.
text[pt] != pattern[pp] 일 때, pp = 0 인 경우, 즉 패턴의 처음부터 일치하지 않는 경우에는 0번째 문자부터 다시 비교해야하므로 pp는 그대로 0이고, pt는 하나 증가한다.
pt++;
case 2.
text[pt] != pattern[pp] 일 때, pp > 0 인 경우, 즉 그 전까지는 일치하다가 패턴의 중간부터 일치하지 않는 경우에는 skip[pp]에 저장된 위치로 이동하여 해당 위치부터 text의 현재 문자를 비교한다.
pp = skip[pp];
case 3.
text[pt] == patter[pp] 일 때, 두 문자가 서로 일치하면, text의 그 다음 문자와 pattern의 그 다음 문자를 서로 비교해주면 된다. 따라서 pt와 pp 둘 다 하나씩 증가한다.
pt++; pp++;
> 전체 코드
int kmpMatch(String text, String pattern){
int pt = 1;
int pp = 0;
int[] skip = new int[pattern.length() + 1];
// 건너뛰기 표 작성
while(pt < pattern.length()){
if(pattern.charAt(pt) == pattern.charAt(pp))
skip[++pt] = ++pp;
else if(pp == 0)
skip[++pt] = pp;
else
pp = skip[pp];
}
// 패턴 검색
pt = pp = 0;
while(pt < text.length() && pp < pattern.length()){
if(text.charAt(pt) == pattern.charAt(pp)){
pt++;
pp++;
}
else if(pp == 0)
pt++;
else
pp = skip[pp];
}
if(pp == pattern.length())
return pt - pp;
return -1;
}