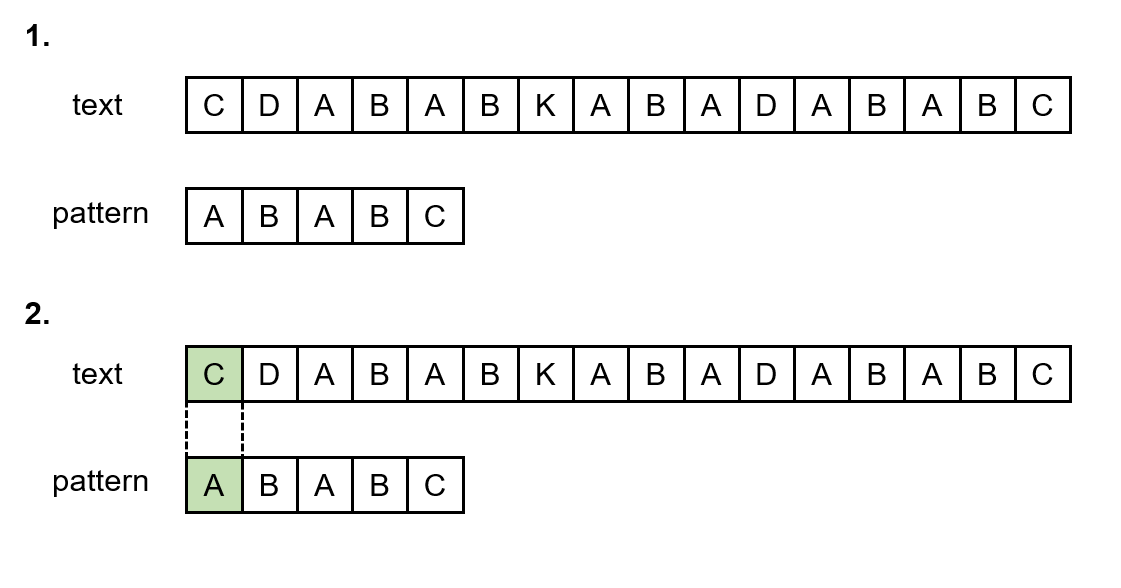
어떤 문자열(T)에서 특정 문자열(P)를 찾을 때 사용하는 알고리즘 예를 들어, 문자열(T) : "CDABABKABADABABC" 문자열(P) : "ABABC" 문자열 T에서 문자열 P를 찾는 방법을 단순하게 완전탐색으로 구현해보면 이중 for문을 통해 다음과 같이 구현해 볼 수 있다. String T="CDABABKABADABABC" String P="ABABC" for(int i=0;i pattern과 pattern의 비교 text와 pattern을 비교한 것과 마찬가지로 pattern과 pattern의 비교도 비슷한 방식으로 이루어진다. 따라서 pattern과 pattern을 비교하는 알고리즘을 이해하고 나면, text와 pattern을 비교하는 알고리즘도 이해하기가 쉬울 것이다. 우선 건너뛰기 표..