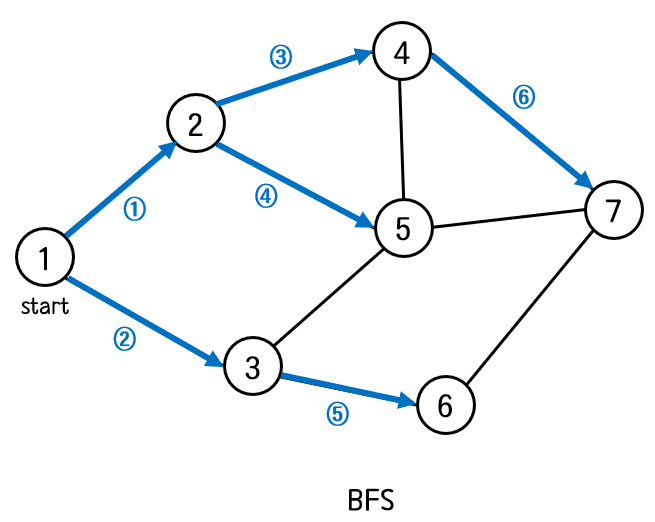
그래프 탐색에는 두 가지 방법이 있다. DFS(Depth First Search) BFS(Breadth First Search) 이번에는 BFS에 대해서 다뤄볼 것이다. DFS(Depth First Search) - 깊이 우선 탐색 그래프 탐색에는 두 가지 방법이 있다. DFS(Depth First Search) BFS(Breadth First Search) DFS 는 이름 그대로 깊이를 우선시 하여 탐색하는 방법이다. '한 우물만 판다' 라는 느낌처럼 한 길만 계속 깊이.. lotuslee.tistory.com BFS는 너비 우선 탐색으로 특정 노드와 연결된 모든 노드들을 우선적으로 탐색한 뒤, 그 중에 하나를 선택하여 또 다시 그와 연결된 모든 노드들을 탐색하는 방식으로 진행된다. 하나의 경로만을 깊..